O: ATEconvert
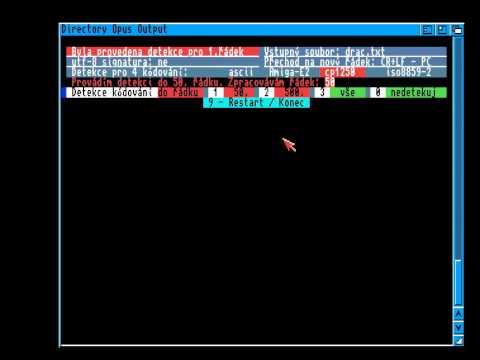
Takže mám rychlost detekce kódování v rámci Pythonu na číslech původní verze. Ale mám to napsané podstatně přehledněji než na původním nedokončeném ATEconvertu. Přes 2200 řádkovej textovej soubor v kódování "cp1250" udělá A1200 za nějakých 42 vteřin. A3000 to pak bude mít tak za 10-15 vteřin. Detekce má něco přes 100 řádků kódu. Optimalizoval jsem to asi z 50 řádkového kódu. Ano, 2 krát větší kód se vykoná mnohonásobně rychleji. Zajímavostí je taky fakt, že když jsem nechal pouze číslovat zpracovávaný řádek, tak se detekce vykonala skoro 4 krát pomaleji. "Slušná" rychlost tisknutí znaku... .
Takže mám rychlost detekce kódování v rámci Pythonu na číslech původní verze. Ale mám to napsané podstatně přehledněji než na původním nedokončeném ATEconvertu. Přes 2200 řádkovej textovej soubor v kódování "cp1250" udělá A1200 za nějakých 42 vteřin. A3000 to pak bude mít tak za 10-15 vteřin. Detekce má něco přes 100 řádků kódu. Optimalizoval jsem to asi z 50 řádkového kódu. Ano, 2 krát větší kód se vykoná mnohonásobně rychleji. Zajímavostí je taky fakt, že když jsem nechal pouze číslovat zpracovávaný řádek, tak se detekce vykonala skoro 4 krát pomaleji. "Slušná" rychlost tisknutí znaku... .

 .
.

Komentovat